Redis高可用
作者:IT王小二
有时候单机形式下的redis性能不足时可能会挂掉导致系统服务异常,为了解决这个问题就有了下面这个内容。
一、Redis主从复制
1. 主从复制的理解
- 类似于MySQL的读写分离,一台Redis(主节点)进行写,其他Redis(从节点)进行读。
- 从节点建议用只读模式 slave-read-only=yes, 若从节点修改数据,主从数据不一致,主节点数据更改后从节点数据又被覆盖,没有任何意义。
- 传输延迟:主从一般部署在不同机器上,复制时存在网络延时问题,redis 提供。 repl-disable-tcp-nodelay 参数决定是否关闭 TCP_NODELAY,默认为关闭。
- 参数关闭时:无论大小都会及时发布到从节点,占带宽,适用于主从网络好的场景。
- 参数启用时:主节点合并所有数据成 TCP 包节省带宽,默认为 40 毫秒发一次, 取决于内核,主从的同步延迟 40 毫秒,适用于网络环境复杂或带宽紧张,如跨机 房。
2. 主从复制基本搭建
如果需要单机搭建参考Linux安装Redis5.0。
操作过程
// 首先进入配置文件目录,复制两份redis配置文件,使用端口号区分
[root@localhost ~]# cd /usr/local/redis/etc/
[root@localhost etc]# cp redis6379.conf redis6380.conf
[root@localhost etc]# cp redis6380.conf redis6381.conf
// redis6379.conf配置的redis节点作为主节点,不需要更改、
// 更改redis6380.conf,redis6381.conf作为从节点的配置文件,vim添加及修改内容
// redis6380.conf 修改端口
port 6380
// 添加内容主节点ip及端口,密码
slaveof 192.168.182.130 6379
masterauth 123456
// redis6381.conf 修改端口
port 6381
// 添加内容主节点ip及端口,密码
slaveof 192.168.182.130 6379
masterauth 123456
// 启动redis6380,redis6381查看效果,因为已经配置过环境变量,所以直接使用redis-server
[root@localhost etc]# redis-server redis6380.conf
[root@localhost etc]# redis-server redis6381.conf
// 查看启动的进程效果
[root@localhost etc]# ps -ef | grep redis
root 7059 1 0 19:29 ? 00:00:02 /usr/local/redis/bin/redis-server 0.0.0.0:6379
root 10404 1 0 20:05 ? 00:00:00 redis-server 0.0.0.0:6380
root 10417 1 0 20:05 ? 00:00:00 redis-server 0.0.0.0:6381
root 10486 8301 0 20:06 pts/0 00:00:00 grep --color=auto redis
// 测试效果,登录redis6379,然后进redis6380和redis6381查看效果
[root@localhost etc]# redis-cli -p 6379 -a 123456
127.0.0.1:6379> set userName SunnyBear
OK
127.0.0.1:6379> exit
[root@localhost etc]# redis-cli -p 6380 -a 123456 interface may not be safe.
127.0.0.1:6380> get userName
"SunnyBear"
127.0.0.1:6380> exit
[root@localhost etc]# redis-cli -p 6381 -a 123456 interface may not be safe.
127.0.0.1:6381> get userName
"SunnyBear"
127.0.0.1:6381> exit命令补充
// 查看状态:
info replication
// 断开主从复制:在 slave 节点,执行
6380:>slaveof no one
// 断开后再变成主从复制
6380:> slaveof 192.168.182.130 63793. 多种主从复制结构
1、一主一从
用于主节点故障转移从节点,当主节点的“写”命令并发高且需要持久化,可以只在从节点开启 AOF(主节点不需要),这样即保证了数据的安全性,也避免持久化对主节点的影响。
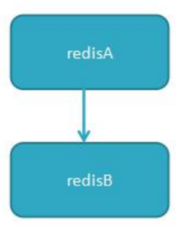
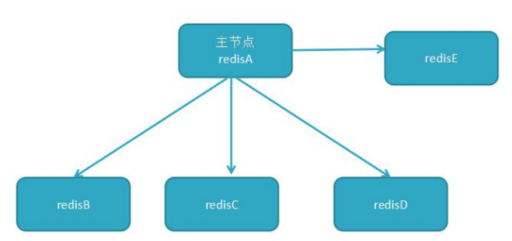
2、一主多从
针对“读”较多的场景,“读”由多个从节点来分担,但节点越多,主节点同步到多节点的次数也越多,影响带宽,也加重主节点的稳定。
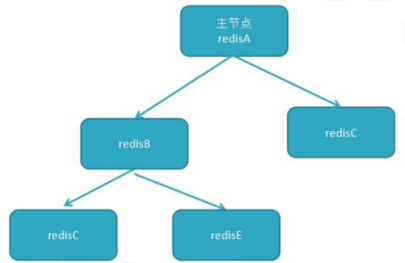
3、树状主从
一主多从的缺点(主节点推送次数多压力大)可下面方案解决,主节点只推送一次数据到从节点 1,再由从节点 2 推送到 11,减轻主节点推送的压力。
4. 复制原理
复制原理
执行slave master port后,与主节点连接,同步主节点的数据,6380:>info replication:查看主从及同步信息。
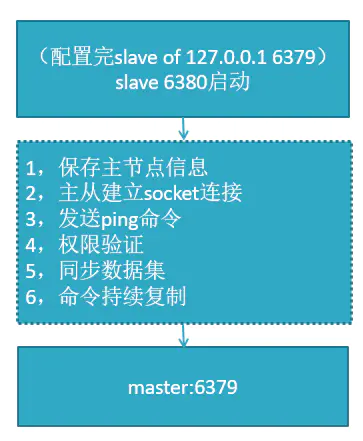
数据同步
redis 2.8 版本以上使用 psync 命令完成同步,过程分“全量”与“部分”复制。
- 全量复制:一般用于初次复制场景(第一次建立 SLAVE 后全量)。
- 部分复制:网络出现问题,从节点再次连主节点时,主节点补发缺少的数据,每次数据增加同步。
- 心跳:主从有长连接心跳,主节点默认每 10S 向从节点发 ping 命令,repl-ping-slave-period 控制发送频率。
二、哨兵模式
1. 哨兵模式理解
为什么有哨兵模式?
redis主节点的能力也是有限的(当然哨兵模式也为无法解决单机redis性能瓶颈问题,需要使用集群),超过了负荷就会挂掉,挂掉了之后就要手动设置主节点,过于麻烦。
什么是哨兵模式?
主节点挂掉之后,通过哨兵机制来选取出新的主节点,其他从节点作为新主节点的从节点,不过整个选举过程也需要十几秒,还是会对服务造成影响。
其实整个过程只需要一个哨兵节点来完成,首先使用Raft算法实现选举机制,选出一个哨兵节点来完成 转移和通知 (选定新主节点和通知其他从节点)。
2. 哨兵模式搭建
在主从复制的基础上
// 从redis-5.0.8目录下拷贝配置文件到redis/etc目录下
[root@localhost /]# cd /usr/local/redis-5.0.8
[root@localhost redis-5.0.8]# cp sentinel.conf ../redis/etc/
// 修改文件名,对应redis哨兵,哨兵个数最好为奇数个,三局两胜,五局三胜,知道吧,我这里用3个哨兵
[root@localhost redis-5.0.8]# cd ../redis/etc/
[root@localhost etc]# mv sentinel.conf sentinel26379.conf
[root@localhost etc]# cp sentinel26379.conf sentinel26380.conf
[root@localhost etc]# cp sentinel26379.conf sentinel26381.conf
// 分别修改三个文件 port 端口号为 26379, 26380, 26381
port 26379
port 26380
port 26381
// 三个文件分别修改内容,搜索sentinel monitor,修改内容为对应的主节点,这个2代表至少两个哨兵认为主节点挂了才代表他挂了
sentinel monitor mymaster 192.168.182.130 6379 2
// 三个文件分别添加内容,主节点连接密码
sentinel auth-pass mymaster 123456
// 分别启动三个哨兵
[root@localhost etc]# redis-sentinel sentinel26379.conf &
[root@localhost etc]# redis-sentinel sentinel26380.conf &
[root@localhost etc]# redis-sentinel sentinel26381.conf &
// 查看进程,哨兵已启动
[root@localhost etc]# ps -ef|grep redis
root 7059 1 0 19:29 ? 00:00:05 /usr/local/redis/bin/redis-server 0.0.0.0:6379
root 14165 1 0 21:06 ? 00:00:00 redis-server 0.0.0.0:6380
root 14177 1 0 21:06 ? 00:00:00 redis-server 0.0.0.0:6381
root 14219 8301 0 21:07 pts/0 00:00:00 redis-sentinel *:26379 [sentinel]
root 14275 8301 0 21:08 pts/0 00:00:00 redis-sentinel *:26381 [sentinel]
root 14327 8301 0 21:09 pts/0 00:00:00 redis-sentinel *:26380 [sentinel]
root 14341 8301 0 21:09 pts/0 00:00:00 grep --color=auto redis这时候可以测试一下,将6379端口的redis kill掉,查看日志选举新主节点。
选举成功的日志信息:
14219:X 01 May 2020 21:16:15.900 # +switch-master mymaster 192.168.182.130 6379 192.168.182.130 6381
14219:X 01 May 2020 21:16:15.900 * +slave slave 192.168.182.130:6380 192.168.182.130 6380 @ mymaster 192.168.182.130 6381
14219:X 01 May 2020 21:16:15.900 * +slave slave 192.168.182.130:6379 192.168.182.130 6379 @ mymaster 192.168.182.130 6381其他配置补充
- sentinel config-epoch mymaster 2。
- 故障转移时最多可以有 2 从节点同时对新主节点进行数据同步
- sentinel failover-timeout mymasterA 180000 // 故障转移超时时间 180s
- 如果转移超时失败,下次转移时时间为之前的 2 倍
- 从节点变主节点时,从节点执行 slaveof no one 命令一直失败的话,当时间超过 180S 时,则故障转移失败
- 从节点复制新主节点时间超过 180S 转移失败
- sentinel down-after-milliseconds mymasterA 300000
- sentinel 节点定期向主节点ping 命令,当超过了 300S 时间后没有回复,可能就认定为此主节点出现故障了……
- sentinel parallel-syncs mymasterA 1
- 故障转移后,1 代表每个从节点按顺序排队一个一个复制主节点数据,如果为3,指 3 个从节点同时并发复制主节点数据,不会影响阻塞,但存在网络和 IO 开销
哨兵的API
// 进入哨兵的命令模式,使用 redis-cli 进入
redis-cli -p 26379
// 查看 redis 主节点相关信息
127.0.0.1:26379> sentinel masters 或 sentinel master mymaster
// 查看从节点状态与相关信息
127.0.0.1:26379> sentinel slaves mymaster
// 查 sentinel 节点集合信息(不包括当前 26379)
127.0.0.1:26379> sentinel sentinels mymaster
// 对主节点强制故障转移,没和其它节点协商
127.0.0.1:26379> >sentinel failover mymaster主观下线和客观下线
- 主观下线
哨兵节点每隔 1 秒对主节点和从节点、其它哨兵节点发送 ping 做心跳检测,当这些心跳检测时间超过 down-after-milliseconds 时,哨兵节点则认为该节点错误或下线,这叫主观下线,这可能会存在错误的判断,需要征求其他哨兵节点的信息。
- 客观下线
当某个哨兵节点首先发现主节点错误或者下线时,此时该哨兵节点会通过指令 sentinel is-masterdown-by-addr 寻求其它哨兵节点对主节点的判断,当超过 quorum(法定人数)个数,此时哨兵节点则认为该主节点确实有问题,这样就客观下线了。
3. 部署建议:
- sentinel 节点应部署在多台物理机(线上环境)。
- 至少三个且奇数个 sentinel 节点。
- 通过以上我们知道,3 个 sentinel 可同时监控一个主节点或多个主节点。
- 监听 N 个主节点较多时,如果sentinel出现异常,会对多个主节点有影响,同时还会造成 sentinel 节点产生过多的网络连接。
- 一般线上建议还是, 3 个 sentinel 监听一个主节点。
4. Java连接操作
哨兵模式下使用 JedisSentinelPool 操作 redis 流程。
- 将三个 sentinel 的 IP 和地址加入 JedisSentinelPool。
- 根据 IP 和地址创建 JedisSentinelPool 池对象。
- 在这个对象创建完后,此时该对象已把 redis 的主节点 (此时 sentinel monitor mymaster 必须写成 192.168.182.130 6379 2,不能为127.0.0.1,不然查询出来的主节点的 IP 在客户端就变成了 127.0.0.1,拿不到连接了) 查询出来了,当客户准备发起查询请求时,调用 pool.getResource()借用一个 jedis 对象,内容包括主节点的 IP 和端口。
- 将得到 jedis 对象后,可执行 jedis.get(“age”)指令了。
三、Redis集群
1. Redis集群理解
为什么要有 redis 集群?
为了解决单机redis性能瓶颈问题,需要使用集群
2. 分布式数据库概念
1、分布式数据库把整个数据按分区规则映射到多个节点,即把数据划分到多个节点上,每个节点负责整体数据的一个子集,比如我们库有 900 条用户数据,有 3 个 redis 节点,将 900 条分成 3 份,分别存入到 3 个 redis 节点。
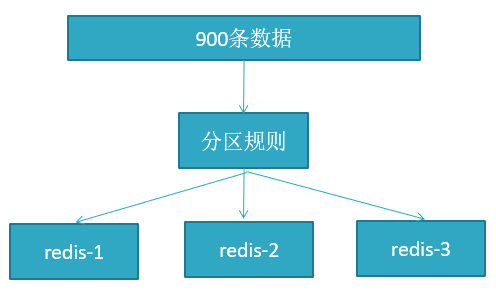
2、分区规则。
常见的分区规则哈希分区和顺序分区,redis 集群有两种(哈希分区、顺序分区), 我们这里使用哈希分区,而哈希分区有三种方式(节点取余、一致性哈希分区和虚拟槽分区)。
Redis Cluster 采用了哈希分区的“虚拟槽分区”方式。
3、虚拟槽分区(槽:slot)。
Redis Cluster采用此分区,所有的键根据 哈希函数(CRC16[key]&16383) 映射到 0-16383 槽内,共 16384 个槽位。
每个节点维护部分槽及槽所映射的键值数据。
哈希函数: Hash()=CRC16[key]&16383 。
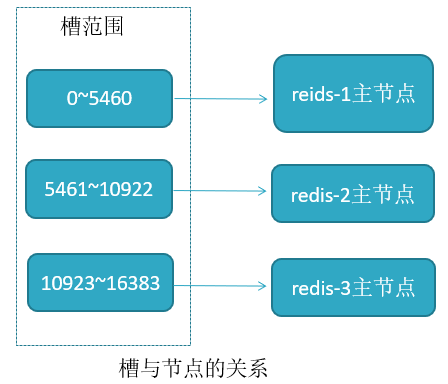
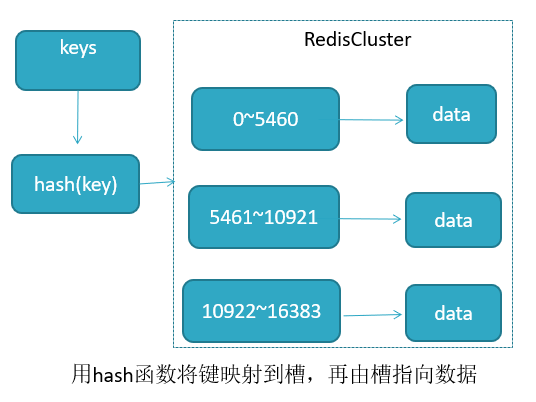
redis 用虚拟槽分区原因: 解耦数据与节点关系,节点自身维护槽映射关系。
4、Redis Cluster的缺陷
- 键的批量操作支持有限,比如 mset, mget,如果多个键映射在不同的槽,就不支持了。
- 键事务支持有限,当多个 key 分布在不同节点时无法使用事务,同一节点是支持事务。
- 键是数据分区的最小粒度,不能将一个很大的键值对映射到不同的节点。
- 不支持多数据库,只有 0,select 0 。
- 主从复制结构只支持单层结构,不支持树型结构。
3. Redis集群基本搭建
在有使用单机 redis 及 主从复制 基础上。
Redis5.0版本集群
// 准备好六个节点文件6380 6381 6382 6480 6481 64382,从 redis-5.0.8 下复制redis.conf文件,然后copy成6个
mkdir /usr/local/redis/etc/cluster
cd /usr/local/redis/etc/cluster
cp /usr/local/redis-5.0.8/redis.conf redis6380.conf
cp /usr/local/redis-5.0.8/redis.conf redis6381.conf
cp /usr/local/redis-5.0.8/redis.conf redis6382.conf
cp /usr/local/redis-5.0.8/redis.conf redis6480.conf
cp /usr/local/redis-5.0.8/redis.conf redis6481.conf
cp /usr/local/redis-5.0.8/redis.conf redis6482.conf
// 统一更改几个地方,以6380为例(注意:5.0之后版本可以使用密码,5.0之前版本不行)
port 6380 // 端口
bind 192.168.182.130 // ip
dir /usr/local/redis/data/cluster/data6380 // RDB/AOF文件保存位置
cluster-enabled yes // 开启集群模式
cluster-node-timeout 15000 // 节点超时时间(毫秒)
cluster-config-file /usr/local/redis/etc/cluster/nodes/nodes-6380.conf // 集群内部配置文件,下次服务器启动时读取此节点配置自动集群
// 创建集群RDB/AOF文件保存目录
mkdir -p /usr/local/redis/data/cluster/{data6380,data6381,data6382,data6480,data6481,data6482}
// 创建集群内部文件目录
mkdir /usr/local/redis/etc/cluster/nodes
// 依次启动6个 redis 节点,以6380为例
redis-server redis6380.conf &
// 6个节点启动后一件启动 redis 集群
// 6480为6380从节点,6481为6381从节点,6482为6382从节点,
// redis.5.0后版本命令,--cluster-replicas 2代表 1 个主节点后面跟着 2 个从节点
redis-cli --cluster create 192.168.182.130:6380 192.168.182.130:6381 192.168.182.130:6382 192.168.182.130:6480 192.168.182.130:6481 192.168.182.130:6482 --cluster-replicas 1集群测试
redis-cli -h 192.168.182.130 -p 6380 -c千万不要忘记加 -c , 不然进入的不是集群环境。
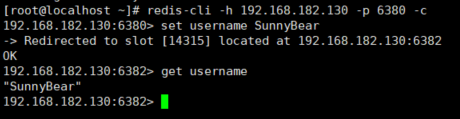
注: 出现上图效果是为什么呢?
这就是应为set username SunnyBear时计算键 username 的槽位对应14315槽位,归6382节点管理,那么重定向到6382将数据存储,当然,这也代表我们集群没问题。
集群状态查看
[root@localhost ~]# redis-cli --cluster check 192.168.182.130:6380
192.168.182.130:6380 (f03ff72a...) -> 0 keys | 5461 slots | 1 slaves.
192.168.182.130:6382 (32b920ec...) -> 1 keys | 5461 slots | 1 slaves.
192.168.182.130:6381 (c1c38eb6...) -> 1 keys | 5462 slots | 1 slaves.
[OK] 2 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.182.130:6380)
M: f03ff72a97fbf47d22ed4abfa0f166f9a814ca94 192.168.182.130:6380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 157f63aa489d5fad4cc6e952abcd2b892ef0d659 192.168.182.130:6480
slots: (0 slots) slave
replicates c1c38eb6828dfce216fcc6a8359ea6a9b0925f9f
S: b1453361bcd44095b515d94653a953712fbf3156 192.168.182.130:6481
slots: (0 slots) slave
replicates 32b920ec9539535823fc79c825f595d1c52be599
S: 463655c25bba5b8632df97c2a4af17d8588ce8f6 192.168.182.130:6482
slots: (0 slots) slave
replicates f03ff72a97fbf47d22ed4abfa0f166f9a814ca94
M: 32b920ec9539535823fc79c825f595d1c52be599 192.168.182.130:6382
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: c1c38eb6828dfce216fcc6a8359ea6a9b0925f9f 192.168.182.130:6381
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.从这里面可以看到6380 6382 6381为主节点和分别分配的槽位:
6380的从节点为6482 6381的从节点为6480 6382的从节点为6481
Redis5.0版本集群新增、删除节点
新增节点
首先
1、准备好两个节点配置文件redis6384.conf,redis6484.conf 2、分别把这两个服务启动起来
然后
1、将 6384 加入到集群主节点。
redis-cli --cluster add-node 192.168.182.130:6384 192.168.182.130:6380 --cluster-master-id f03ff72a97fbf47d22ed4abfa0f166f9a814ca94这时候可以查看一下 redis-cli --cluster check 192.168.182.130:6384 状态,6384节点已经加入集群,并且是一个主节点,但是没有分配槽位,此时无法进行存储数据。
M: fd629c15ae39d99d76a2b80c951be1fb5c9be7c3 192.168.182.130:6384
slots: (0 slots) master2、将 6484 加入到集群,并且作为 6384 的从节点。
redis-cli --cluster add-node 192.168.182.130:6484 192.168.182.130:6384 --cluster-slave --cluster-master-id fd629c15ae39d99d76a2b80c951be1fb5c9be7c3这时候可以查看一下 redis-cli --cluster check 192.168.182.130:6484 状态,已经成为了 6384 的从节点。
3、给新加的主节点 6384 分配槽位,分配1000个槽位。
redis-cli --cluster reshard 192.168.182.130:6380
// 中途会提示几个选项
How many slots do you want to move (from 1 to 16384)? 1000 //分配多少个槽位 1000
What is the receiving node ID? fd629c15ae39d99d76a2b80c951be1fb5c9be7c3 // 转移到新节点id(即新增主节点id)
Source node #1: all // 从哪里分配槽位,all代表所有主节点分配,也可以输入cluster-master-id
Do you want to proceed with the proposed reshard plan (yes/no)? yes // 是否继续分配:yes然后再次 redis-cli --cluster check 192.168.182.130:6484 查看状态,发现槽位已经分配。
删除节点
首先需要删除从节点,不然集群会认为主节点故障,从而让从节点变成主节点。
查找到 6484 从节点 id,然后执行命令。
redis-cli --cluster del-node 192.168.182.130:6484 1b811b75a527da59ec66aca76a3b259568639374将 要删除的主节点 的 槽位 分配给其他主节点,与增加类似,如果不移出会导致数据丢失。
redis-cli --cluster reshard 192.168.182.130:6384
How many slots do you want to move (from 1 to 16384)? 1000
What is the receiving node ID? 32b920ec9539535823fc79c825f595d1c52be599 // 6382节点id
Source node #1: fd629c15ae39d99d76a2b80c951be1fb5c9be7c3
Source node #2: done
Do you want to proceed with the proposed reshard plan (yes/no)? yes槽位数据转移给别的主节点后,删除节点。
redis-cli --cluster del-node 192.168.182.130:6384 fd629c15ae39d99d76a2b80c951be1fb5c9be7c3Redis5.0之前版本集群
Redis5.0之前的版本集群需要借助ruby,安装 ruby 和 redis-3.3.0.gem 。
// 进入 /usr/local 目录下载 ruby 和 redis-3.3.0.gem
cd /usr/local
wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
wget http://rubygems.org/downloads/redis-3.3.0.gem
// 解压
tar -zxvf ruby-2.3.1.tar.gz
// 进入 ruby-2.3.1 目录
cd ruby-2.3.1
// 设置安装目录
./configure -prefix=/usr/local/ruby
// 编译安装
make && make install
// 安装 redis-3.3.0.gem,如果没有 gem 需要安装 yum install gem -y
gem install -l redis-3.3.0.gem
// 复制 /usr/local/redis-5.0.8/src/redis-trib.rb 文件到 /usr/local/redis/bin/ 目录下
cp /usr/local/redis-5.0.8/src/redis-trib.rb /usr/local/redis/bin/Redis5.0之前集群。
// 省略准备6个节点文件及启动6个节点操作。。(注意,不要设置 requirepass 密码,设置后 redis-trib访问不了)
// redis5.0以前版本命令
redis-trib.rb create --replicas 1 192.168.182.130:6380 192.168.182.130:6381 192.168.182.130:6382 192.168.182.130:6480 192.168.182.130:6481 192.168.182.130:64824. Redis集群节点通信
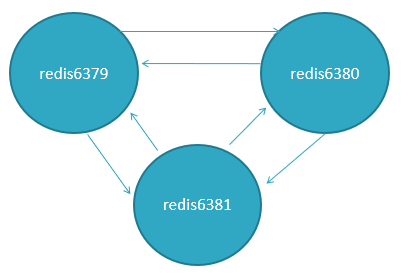
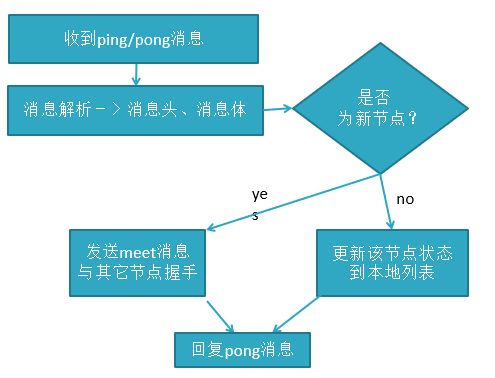
节点之间采用Gossip协议进行通信,Gossip协议就是指节点彼此之间不断通信交换信息。
当主从角色变化或新增节点,彼此通过ping/pong进行通信知道全部节点的最新状态并达到集群同步。
Gossip协议(了解)
Gossip协议的主要职责就是信息交换,信息交换的载体就是节点之间彼此发送的Gossip消息,常用的Gossip消息有ping消息、pong消息、meet消息、fail消息。
- meet消息:用于通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信完后,接收节点会加入到集群中,并进行周期性ping pong交换。
- ping消息:集群内交换最频繁的消息,集群内每个节点每秒向其它节点发ping消息,用于检测节点是在在线和状态信息,ping消息发送封装自身节点和其他节点的状态数据。
- pong消息:当接收到ping meet消息时,作为响应消息返回给发送方,用来确认正常通信,pong消息也封闭了自身状态数据。
- fail消息:当节点判定集群内的另一节点下线时,会向集群内广播一个fail消息。

消息解析过程