MySQL体系结构概览
作者:IT王小二
一条 SQL 语句在 MySQL 中怎么执行的呢,这篇就来认识下 MySQL 的各个组件的作用。
一、结构组件
首先需要 MySQL 安装的小伙伴们可以访问本站搜索相关文章。
先上个图,小二自己画的,绝对的高清无码,嘿嘿。不足之处欢迎指正哈。
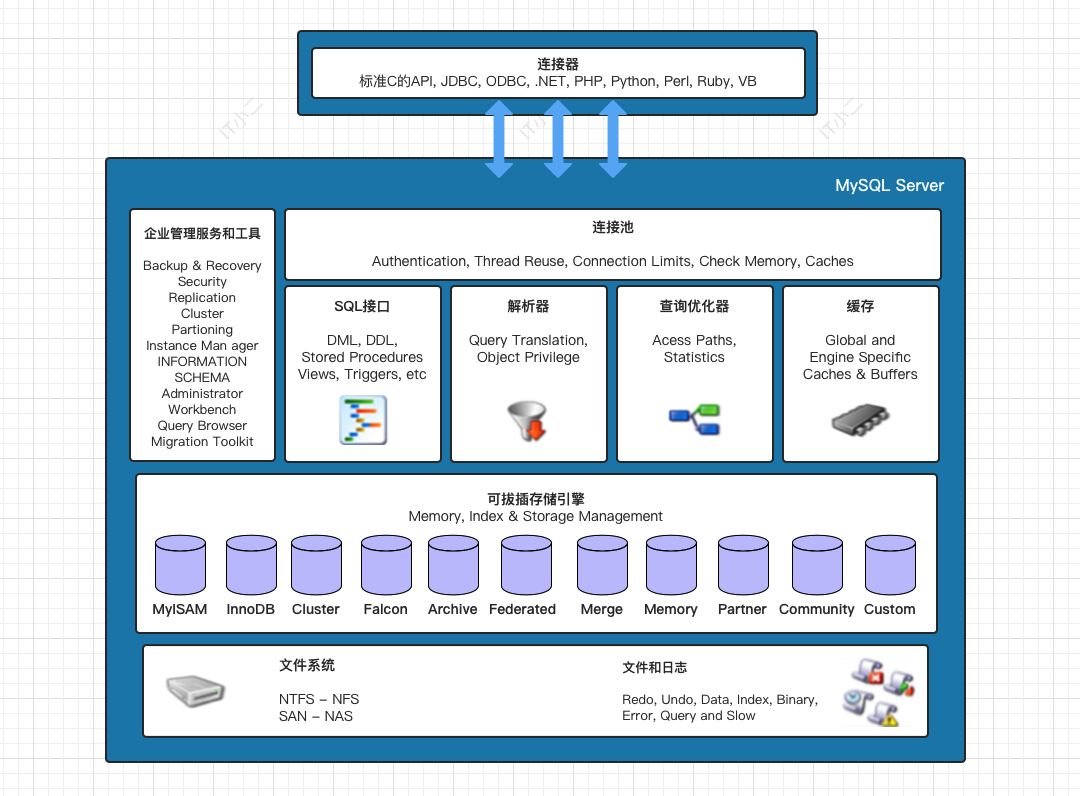
企业管理服务和工具
系统管理和控制工具,例如 MySQL 备份恢复、MySQL 复制、MySQL 集群等工具。
连接池
负责监听对客户端向 MySQL Server 端的各种请求,建立连接、权限校验、维持和管理连接,通信方式是半双工模式,数据可以双向传输,但不能同时传输。
- 单工:数据单向发送。
- 半双工:数据双向传输,但不能同时传输。
- 全双工:数据双向传输,可以同时传输。
那么 MySQL 是怎么保存连接得嘞?
每个成功连接 MySQL Server 的客户端请求都会创建或分配一个线程,在内存中分配一块空间存储对应的会话信息,其中包含权限等信息,该线程负责客户端与 MySQL Server 端的通信,接收客户端发送的命令,传递服务端的结果信息等。
用户的权限表在系统表空间的 mysql 库中的 user 表中,这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
一些有点用的命令。
MySQL 允许最大的连接数
show variables like '%max_connections%';
这个值可以在 my.cnf 文件中配置,Docker 安装完 MySQL 版本为 5.7.36 默认值为 151 个最大允许连接数。
项目中可能会遇到 MySQL: ERROR 1040: Too many connections 的异常情况,造成这种情况的原因有两个。
- 一种是 MySQL 配置文件中
max_connections值过小,可以在配置文件my.cnf中添加max_connections参数增大最大连接数,例如max_connections = 500。 - 一种是访问量过高,MySQL 服务器抗不住,这个时候就要考虑增加从服务器分散读压力。
查询当前 MySQL 服务器接收所有的连接信息
show processlist;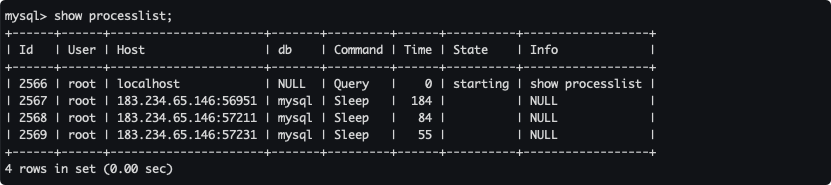
State 状态常见的就是 Sleep 和 Query,详解自行度娘、谷哥,一般也没啥人看。
- Sleep:线程正在等待客户端发送新的请求。
- Query:线程正在执行查询或者正在将结果发送给客户端。
数据库闲置连接超时时间
-- 非交互式超时时间,如 JDBC 程序
show global variables like 'wait_timeout';
-- 交互式超时时间,如数据库工具
show global variables like 'interactive_timeout';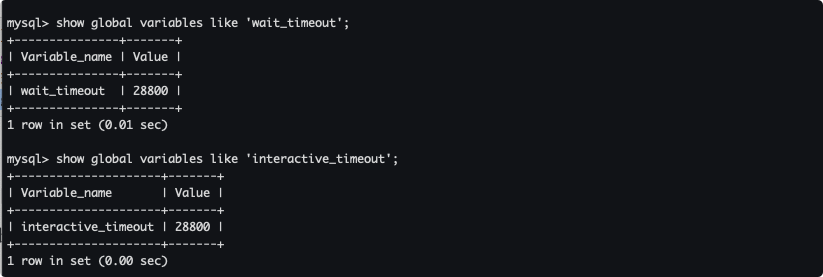
可以看到超时时间都是默认8小时,即当客户端状态连接后为 Sleep 的时候,如果8小时没有收到请求那么就会断开连接。
MySQL状态分析
show global status like 'Thread%';
- Threads_cached:服务器端缓存连接
- Threads_connected:当前打开的连接数
- Threads_created:创建的线程数
- Threads_running:正在运行的线程
SQL接口
负责接收用户 SQL 命令,如 DML,DDL 和存储过程等,并将命令发送到其他部分,并接收其他部分返回的结果数据,将结果数据返回给客户端。
关于这个组件小二也有点懵,那么具体分发到哪些组件上面去了,翻了很多资料基本就是一句话解释的,以后翻翻高性能 MySQL 看看有详细描述没~
查询缓存
首先需要说明:在 MySQL8.0 中已经删除了查询缓存,MySQL5.7 中仍然存在查询缓存。
如果开启了 MySQL 缓存的话,成功获取一个 MySQL 连接后,会先到查询缓存看看,之前是不是执行过这条语句。
如果之前执行过,那么这条语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段,通过存储引擎去查询。执行完成后,执行结果会被存入查询缓存中。
如果命中缓存的话那么速度确实会很快,但是...但是...MySQL 的这个缓存功能往往却比较鸡肋,为什么这么说呢?
涉及到缓存,那当然就有和源数据保持一致性的问题,或者说同步的问题。
那么想一想,MySQL 如果要保持查询查询缓存数据结果的一致性,同时那个表经常性的更新数据,那么每更新一条数据,MySQL 为了保持一致性就要把该表所有的 key 全部查询一次,那么对于一个频繁更新的表来说那么 MySQL 的压力就太大了。
所以...,MySQL 选择了最简单粗暴的方式,如果该表一更新数据,就从查询缓存删除该表所有的 key,即从查询缓存删除不该表相关的所有查询语句缓存。
那么既然说是鸡肋,那当然还是有一点点用的,只要使用得当,那么什么场景下查询缓存可以发挥那么一点点作用呢?
如果说在项目中不想引入 Redis,那么这个查询缓存能不能在某些方面加快一些查询速度呢,当然是可以的。
既然频繁更新的表不适用查询缓存,那么我们开发中几个月才会更新一次的表不就正好合用吗,例如常见的系统配置表、字典表等,同时 MySQL 也正好提供了按需使用的策略方式。
怎么按需使用呢?
首先把查询缓存开启按需配置,查询 show global variables like "%query_cache_type%"; 如果结果为 OFF,那么就需要在 MySQL 配置文件 my.cnf 中配置如下参数后重新启动 MySQL 即可。
# 查询缓存开启,OFF 关闭,ON 开启
query_cache_type = ON
# 缓存策略,0代表关闭查询缓存 OFF,1代表开启 ON,2代表 DEMAND,DEMAND代表当sql语句中有SQL_CACHE 关键词时才缓存
query_cache_type=2如果你和小二一样的的方式安装的 MySQL,docker 安装默认没有 my.cnf 文件的,那么需要自己在 docker 映射目录 /itwxe/dockerData/mysql/conf 下面创建文件 my.cnf,添加如下内容使用 docker restart mysql 重启容器即可开启查询缓存。
[mysqld]
query_cache_type = ON
query_cache_type = 2添加 my.cnf 后重启容器,登录 MySQL 后可以看到查询缓存已经开起来了。

那么接下来只需要在需要缓存结果的查询语句上面加上一个 SQL_CACHE 显示指定即可,例如:
SELECT SQL_CACHE * FROM test_innodb WHERE id = 6;查看一下缓存的运行信息。
show status like'%Qcache%';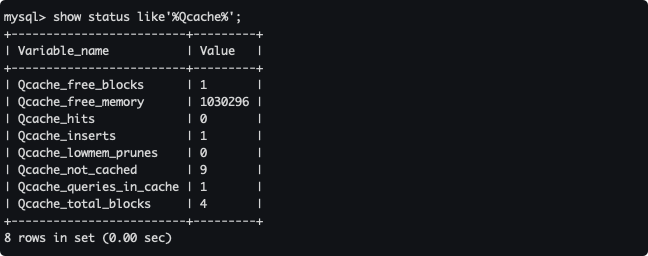
结果说明:
- Qcache_free_blocks:表示缓存中相邻内存块的个数。数目大说明可能有碎片。
- Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多了,还是不够用,可以根据实际情况做出调整。缺省从图中可以看到默认大小为 1Mb(图中以b为单位),可以在
my.cnf中通过query_cache_size = 20M指定缓存大小。 - Qcache_hits:表示有多少次命中缓存。
- Qcache_inserts:表示多少次未命中然后插入,意思是新的查询 SQL 请求在缓存中未找到,需要执行查询处理,执行查询处理后把结果 insert 到查询缓存中。
- Qcache_lowmem_prunes:该参数记录有多少条查询因为内存不足而被移除出查询缓存,通过这个值可以适当的调整缓存大小。
- Qcache_not_cached:表示因为 query_cache_type 的设置而没有被缓存的查询数量。
- Qcache_queries_in_cache:当前缓存中缓存的查询数量。
- Qcache_total_blocks:缓存中块的数量。
各个参数和缓存的效果可以多查询几遍试试就明白啦,鸡肋还是有一点点用的,哈哈,当然你要是已经有了 Redis 等缓存中间件就不需要查询缓存啦,同时 MySQL8.0 中也已经移除查询缓存功能。
解析器
负责将接收到的 SQL 命令解析和验证。解析器主要功能:
- 将 SQL 语句分解成数据结构,并将这个结构传递到后续步骤,以后 SQL 语句的传递和处理就是基于这个结构的。说人话就是将我们写的 SQL 语句分解成 MySQL 认识的语法往下传递。
- 如果在分解构成中遇到错误,那么就说明这个 sql 语句是不合理的。说人话就是看看我们写的 SQL 语句有没有语法错误。
查询优化器
负责 SQL 语句在查询之前对查询进行优化,这个过程会使用 optimizer trace 优化查询 SQL,然后计算各种可以使用的索引和全表扫描的查询成本相比较,选择最优的查询方式。
optimizer trace 工具会在后面的文章中说到,MySQL 到底通过什么规则计算的查询成本的,为什么有时候明明有可以使用的索引最后还是走的全表扫描,在后面章节小二会提到哦,欢迎各位小伙伴关注。
可拔插存储引擎
存储引擎就是如何管理操作数据(存储数据、更新数据、查询数据等)的一种方法,当然在 MySQL 中。而可拔插就可以理解为 MySQL 提供了一个接口,只要遵循规则即可以自定义实现存储引擎,Java中接口与实现类的关系。
文件系统
文件系统主要是将数据库的数据存储在操作系统的文件系统之上,并完成与存储引擎的交互。例如数据库文件,表文件和各种日志文件(bin log、redo log、undo log等)。
二、一条SQL语句的执行过程概览
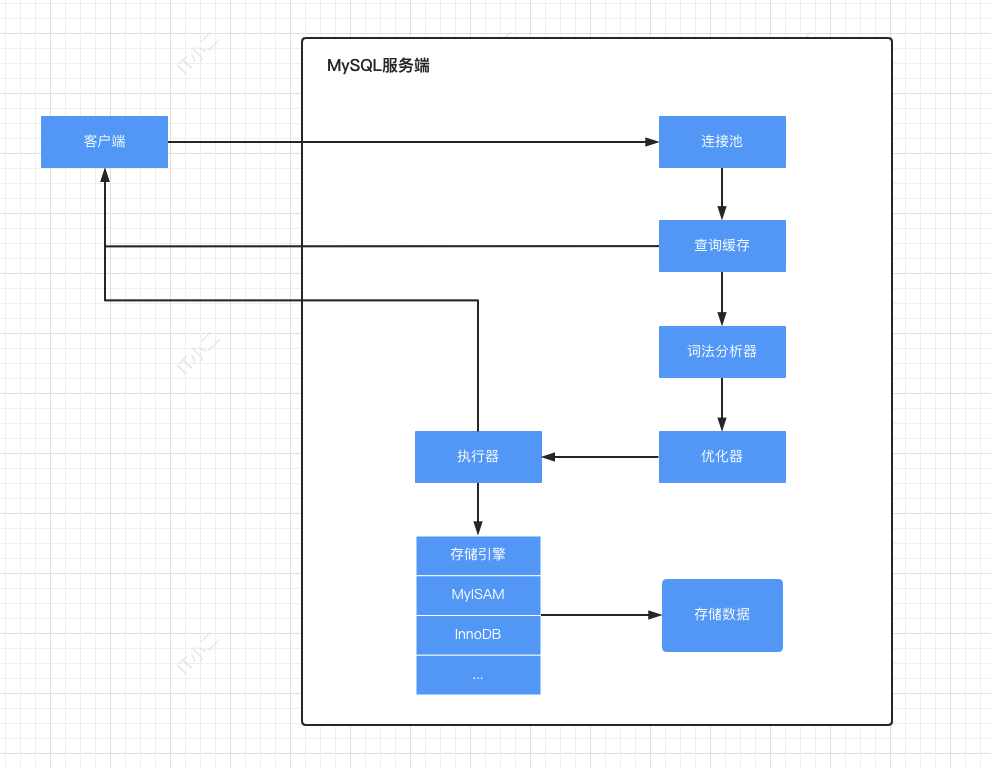
相信仔细看了查询缓存的都不会问小二为啥新增、修改、删除都要走查询缓存了吧,嘿嘿。总览到此结束,接下来下一篇就讲讲 Explain 执行计划。